

Мы в GeekBrains стараемся регулярно проводить офлайн-мероприятия для разных факультетов, а недавно ещё и стали писать про них в блоге — например, про хакатон для игровых дизайнеров и разработчиков или про митап для учеников GeekSchool и их родителей. В субботу 8 февраля мы принимали новых гостей — студентов факультетов искусственного интеллекта и аналитики Big Data.
На митап в офисе Mail.Ru Group мы пригласили выступить троих наших хорошо знакомых преподавателей — Сергей Ширкина, Фрэнка Шихалиева и Никиту Баранова — а также «звёздного гостя» — Валерия Бабушкина, директора по моделированию и анализу данных в X5 Retail Group, топ-50 в мировом рейтинге специалистов по машинному обучению.

Вы никогда не наймёте дата-сайентиста. С этого утверждения начал своё выступление Валерий.
Вот существует computer science — ряд тесно связанных дисциплин. Но такого специалиста, как computer scientist никто не нанимает. Ищут и берут на работу архитекторов, девопсов, тестировщиков, админов, фронтендеров и бэкендеров на конкретном стеке.Data science — это тоже ряд тесно связанных дисциплин. Работодатели здесь ещё не особо разборчивы. Можно зайти в 10 разных компаний, ищущих дата-сайентистов, и во всех будут совершенно разные наборы задач:
- перекладывать таблички в Excel
- поднять кластер на несколько петабайт
- построить real-time систему компьютерного зрения
- выводить чат ботов в промышленных объёмах
- строить визуализацию в Tableau
- писать скрипты на SQL
- выводить рекомендательные системы в прод
- проводить A/B-тестирование
- отвечать на вопросы
Дата-сайентист — это слишком общий ответ на все эти вопросы. Нужно более точно определять своего дата-сайентиста мечты. По факту, в каждом из них в разной степени сочетаются знания в трёх областях. Это бизнес (сама потенциальная сфера применения data science), разработка/devops/SWE (software engineering) и математика (машинное обучение, алгоритмы, статистика). В зависимости от соотношения всего этого в конкретном специалисте Валерий выделяет шесть видов дата-сайентистов:
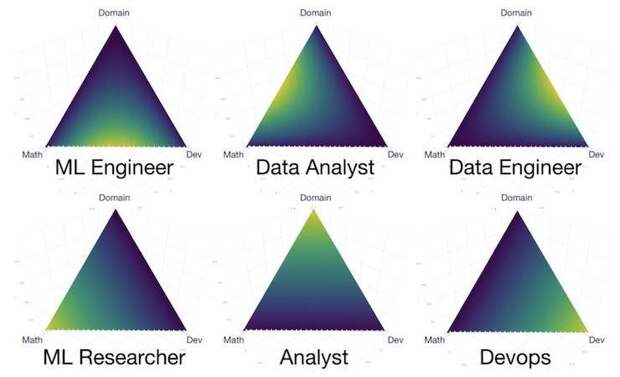
Чем светлее оттенок, тем больше экспертиза в соответствующей области
Таким образом, чтобы стать дата-сайентистом, стоит понимать, чем конкретно вы хотите заниматься. Затем определиться, какие навыки для этого нужны — SQL, Python, математика, статистика. Изучить тематические платформы, сообщества, хакатоны — ods, Kaggle, sdsj. И конечно же, не бояться собеседований.
Сергей Ширкин, декан факультетов искусственного интеллекта и аналитики Big Data, а также дата-сайентист Dentsu Aegis Network Russia, рассказал о перспективах квантового машинного обучения. Этим задачам посвящён проект Qiskit — опенсорсный фреймворк для разработки с использованием квантовых вычислений. У Qiskit есть репозиторий на Github, а также свой хаб на Stackexchange, где можно задать все вопросы. Кроме того, в помощь разработчикам создана библиотека Pennylane — Python-библиотека для квантового машинного обучения, автоматической дифференциации и оптимизации гибридных вычислений.

Обратить внимание на квантовые вычисления стоит хотя бы потому, что в октябре 2019 года Google заявил о достижении квантового превосходства. Квантовый компьютер компании за 3 минуты 20 секунд выполнил расчёт, на который самому мощному в мире классическому суперкомпьютеру IBM Summit понадобилось бы около 10 тысяч лет.
Фрэнк Шихалиев, куратор курса «ML в страховании» на факультете искусственного интеллекта GeekBrains и основатель проекта Mindset, отошёл от технических тем и рассказал о своём опыте перехода от работы в штате к фрилансу, к собственному проекту.
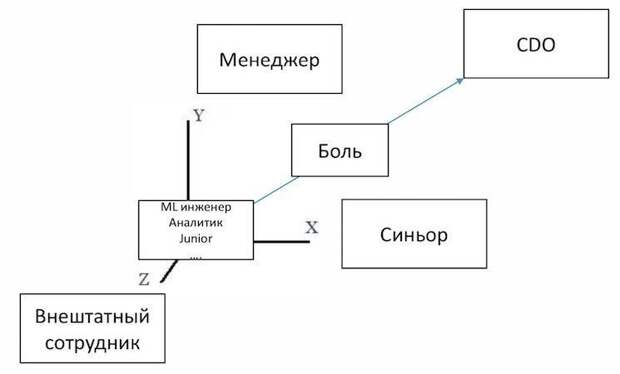
Карьерный путь IT-специалиста развивается в одной плоскости, позиция на которой определяется уровнем хард- и софт-скиллов. Для аналитика конечная точка здесь — CDO (Chief Data Officer), и путь к ней весьма и весьма тернист. Но есть возможность выйти из плоскости и ступить на ось Z!
Преимущества работы на фрилансе и причины ухода от работы в штате уже обсуждали много раз. Пожалуй, стоит ещё раз оценить недостатки:
- Нет понятия заслуженного отпуска, но есть более менее свободный график
- Больничных нет, но все с пониманием относятся к этому
- Надо немного разбираться с налогами и бухгалтерией
- Бывает нервно
«Одинокий» фриланс может трансформироваться в большой проект благодаря знакомствам — бывшие коллеги становятся новыми партнёрами. Так случилось и с Фрэнком. Сейчас вместе с двумя партнёрами они реализуют ML-проекты в разных отраслях — строительстве, страховании. Среди самых востребованных технических областей Фрэнк отметил:
- data management и warehousing
- построение моделей
- автоматизация внедрения ML моделей в бизнес-процессы
- автоматическое тестирование
- консультирование и Proof of Concept бизнес-идей
А вот где можно искать проекты и потенциальных партнёров:
- Профессионалы 4.0
- Upwork.com
- Headhunter
- тендеры
Напоследок Фрэнк поделился исследованием доходов фрилансеров и дал общую последовательность действий для тех, кто решился уходить в свободное плавание:
- иметь запас средств
- выбрать одно направление
- учиться
- найти любого первого заказчика
- начать проект удалённо и заранее
- работать по вечерам и выходным
- расширять знания и степень ответственности
- переходить на внештатную работу целиком
- делегировать, делиться знаниями и проектами
- масштабироваться
Для тех, кому в программе не хватало технических докладов, мы попросили выступить Никиту Баранова — преподавателя GeekBrains на курсе «Библиотеки Python для Data Science», дата-сайентиста OneFactor. Он рассказал о преимуществах Spark в качестве основного инструмента для дата-сайентиста. В ряде задач по распределённой обработке данных Spark имеет преимущество над MapReduce — стандартного обработчика Hadoop. Но Spark не лишён недостатков, которые Никита также упомянул. Вообще, его выступление заслуживает отдельного поста; поделимся лишь списком преимуществ и недостатков фреймворка, которые Никита сформулировал:

Чтобы представлять, что спрашивают на собеседованиях дата-сайентистов, Никита очень советовал смотреть задачки на Interview-mds.ru — там всё «основано на реальных событиях».
Если вы тоже хотите поучаствовать в наших мероприятиях для студентов факультетов искусственного интеллекта и аналитики Big Data, ждём вас в GeekUniversity! Ближайшие потоки стартуют 15 февраля ;)
